Version: 0.3.38
Graphs as Data Structures#
Besides being a mathematical concept, a graph is also a data structure. Intuitively, the queries one runs against a graph include:
Graph ADT#
There is no agreement on what the graph abstract data type should be. There are indeed many operations that one can perform on a graph, finding cycles, components, unreachable vertices, etc. Graphs are highly application dependent. I put below what seems to me like a common minimal set of operations:
- empty
Create a new empty graph, that is an graph with no vertex or edge.
- add vertex
Add a new vertex to the given graph. What identifies the vertex, as well as the information its carries depend on the problem and or the selected internal representation.
- remove vertex
Delete a specific vertex from the given graph. Either this raises an error if the selected vertex still has incoming or outgoing edges, or it removes these edges as well.
- add edge
Create a new edge between the two given vertices. What identifies this edge as well as the information it carries depend on the problem and the chosen internal representation.
- remove edge
Remove the selected edge.
- edges from
Returns the list of edges whose source is the given vertex
- edges to
Returns the list of edges whose target is the given vertex
- is_adjacent
True if an only if there exist an edge between the two given vertices
Graph Representations#
There are many ways to implement the graph ADT above, from a simple list of edges to more complicated structures using hashing. As always, the one to use depends on the problem at hand. Let see the most common ones.
In the general case, there is some information attached to either the vertex, the edges, or to both. The internal representation we choose impact however the implementation (and the efficiency) of the operations.
Operations |
Edge List |
Adjacency List |
Adjacency Matrix |
|---|---|---|---|
add vertex |
O(1) |
O(1) |
|
remove vertex |
O(V) |
O(V) |
|
add edge |
O(1) |
O(1) |
|
remove edge |
O(E) |
O(V+E) |
|
edges from |
O(E) |
O(deg(v)) |
|
edges to |
O(E) |
O(deg(v)) |
|
is adjacent |
O(E) |
O(1) |
Edge List#
The simplest solution is simply to store a sequence of edges, where each edge includes a source vertex, a target vertex and a label. With this design a vertex is identified by its index in the underlying list of vertices, and an edge by its index in the underlying list of edges.

Overview of an edge list implementation. Vertices and edges are records, stored into separate sequences.#
While simple, the main downside of this scheme is that most of
operations on graphs rely on linear search to find either the vertex
or the edge of interest. Listing 1.11 illustrates this
issue on the edgesFrom method, where we have to iterate through
all the edges to find those whose source vertex match the given one.
public class EdgeList<V, E> {
class Edge {
private int source;
private int target;
private E label;
}
private List<V> vertices;
private List<Edge> edges;
public List<Integer> edgesFrom(int source) {
final var result = new ArrayList<Integer>();
for(var edge: this.edges) {
if (edge.source == source) {
result.add(edge);
}
}
return result;
}
// Etc.
}
Adjacency List#
Another possible representation is the adjacency list: Each vertex gets its own list of incident edges. Often, store a hash table to retrieve specific vertex faster. When edges have no label/payload, each vertex is associated with the list of adjacent vertices (so the name “adjacency list”).
The benefit of the this adjacency list is that is speed up the retrieval of incoming and outgoing edges. These are often very useful operation, for example, to traverse the graph (see Graph Traversals)
public class AdjacencyList<V, E> {
class Edge {
int source;
int target;
E payload;
// etc.
}
class Vertex {
V payload;
List<Edge> incidentEdges;
// etc.
}
private List<Vertex> vertices;
private List<Edge> edges;
public List<Integer> edgesFrom(int source) {
final var result = new ArrayList<Integer>();
for(var edge: this.vertices[source].incidentEdges) {
if (edge.source == source) {
result.add(edge);
}
}
return result;
}
// etc.
}
Adjacency Matrix#
Note
Graphs can quickly become very large. Take social media for instances with millions of users, or package dependencies in Python of JavaScript. Such large graphs requires dedicated storage solution, more like databases. Relational databases such as MySQL are however inappropriate and dedicated solution exists such as such as Neo4j for instance.
Graph Traversals#
As we have seen for trees, one may need to navigate through the structure of the graph, for instance to find whether there is a path between two vertices.
We can adapt the two traversal strategies we have studied for trees, namely, the breadth-first and the depth-first traversal. The only difference is that graphs may contain cycles, and that we remember which vertices we have already “visited” to avoid “looping” forever in a cycle.
As we progress through a graph we need to keep track of two things:
The vertices that we have discovered but not yet processed. We will name these
pendingverticesThe vertices that we have already visited (i.e., processed). We will name these the
visitedvertices.
Depth-first Traversal#
Intuitively, a depth-first traversal never turns back, except once it reaches a dead-end, either because the vertex it has reached has no outgoing edge, or because it has already “visited” all the surrounding vertices. The depth-first traversal would proceed as follows:
Add the entry vertex to the sequence of pending vertices
While there are pending vertices,
Take out the last pending vertex added
If that vertex is not in the set of visited ones
Add it to the set of visited vertices
Add all vertices that can be reached from there
depth_first_alg below shows a Java implementation of this
algorithm. Note the use of a stack (see Line 3) which forces the
extraction of the last inserted pending vertex.
1public void depthFirstTraversal(Graph graph, Vertex entry) {
2 final var visited = new HashSet<Vertex>();
3 final var pending = new Stack<Vertex>();
4 pending.push(entry);
5 while (!pending.isEmpty()) {
6 var current = pending.pop();
7 if (!visited.contains(current)) {
8 System.out.println(current);
9 visited.add(current);
10 for (var eachEdge: graph.edgesFrom(current)) {
11 pending.push(eachEdge.target)
12 }
13 }
14 }
15}
Consider for example depth_first_example below, which shows
a “friendship” graph. Vertex represent persons, whereas an edge between two
persons indicates they know each other. Edges are bidirectional and
can be navigated both ways. Starting from “Denis”, this depth-first
traversal will reach the vertices in the following order: Denis,
Frank, Lisa, John, Mary, Olive, Erik, Peter, and Thomas.
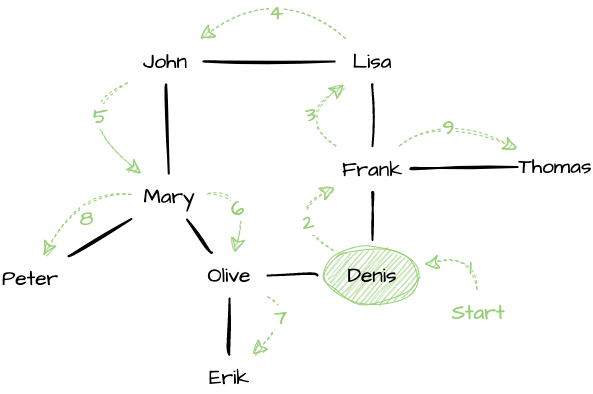
Traversing a graph “depth-first”, starting from the vertex “Denis” (assuming neighbors are visited in alphabetical order). This yields the following order: Denis, Frank, Lisa, John, Mary, Olive, Erik, Peter, Thomas.#
Let see how the visited and pending variables evolve in this
example.
Step |
Current |
Pending |
visited |
See lines |
|---|---|---|---|---|
0 |
\(D\) |
\(()\) |
\(\{\}\) |
Line 6 |
1 |
\(D\) |
\(()\) |
\(\{D\}\) |
Line 9 |
2 |
\(D\) |
\((O,F)\) |
\(\{D\}\) |
Line 10-12 |
3 |
\(F\) |
\((O)\) |
\(\{D\}\) |
Line 6 |
4 |
\(F\) |
\((O)\) |
\(\{D,F\}\) |
Line 9 |
5 |
\(F\) |
\((O,T,L,D)\) |
\(\{D,F\}\) |
Line 10-12 |
6 |
\(D\) |
\((O,T,L)\) |
\(\{D,F\}\) |
Line 6 |
7 |
\(L\) |
\((O,T)\) |
\(\{D,F\}\) |
Line 6 |
8 |
\(L\) |
\((O,T)\) |
\(\{D,F,L\}\) |
Line 9 |
9 |
\(L\) |
\((O,T,J,F)\) |
\(\{D,F,L\}\) |
Line 10-12 |
10 |
\(F\) |
\((O,T,J)\) |
\(\{D,F,L\}\) |
Line 6 |
11 |
\(J\) |
\((O,T)\) |
\(\{D,F,L\}\) |
Line 6 |
12 |
\(J\) |
\((O,T)\) |
\(\{D,F,J,L\}\) |
Line 9 |
13 |
\(J\) |
\((O,T,M,L)\) |
\(\{D,F,J,L\}\) |
Line 10-12 |
14 |
\(L\) |
\((O,T,M)\) |
\(\{D,F,J,L\}\) |
Line 6 |
15 |
\(M\) |
\((O,T)\) |
\(\{D,F,J,L\}\) |
Line 6 |
16 |
\(M\) |
\((O,T)\) |
\(\{D,F,J,L,M\}\) |
Line 9 |
17 |
\(M\) |
\((O,T,P,O,J)\) |
\(\{D,F,J,L,M\}\) |
Line 10-12 |
18 |
\(J\) |
\((O,T,P,O)\) |
\(\{D,F,J,L,M\}\) |
Line 6 |
19 |
\(O\) |
\((O,T,P)\) |
\(\{D,F,J,L,M\}\) |
Line 6 |
20 |
\(O\) |
\((O,T,P)\) |
\(\{D,F,J,L,M,O\}\) |
Line 9 |
21 |
\(O\) |
\((O,T,P,M,E,D)\) |
\(\{D,F,J,L,M,O\}\) |
Line 10-12 |
22 |
\(D\) |
\((O,T,P,M,E)\) |
\(\{D,F,J,L,M,O\}\) |
Line 6 |
23 |
\(E\) |
\((O,T,P,M)\) |
\(\{D,F,J,L,M,O\}\) |
Line 6 |
24 |
\(E\) |
\((O,T,P,M)\) |
\(\{D,E,F,J,L,M,O\}\) |
Line 9 |
25 |
\(E\) |
\((O,T,P,M,O)\) |
\(\{D,E,F,J,L,M,O\}\) |
Line 10-12 |
26 |
\(O\) |
\((O,T,P,M)\) |
\(\{D,E,F,J,L,M,O\}\) |
Line 6 |
27 |
\(M\) |
\((O,T,P)\) |
\(\{D,E,F,J,L,M,O\}\) |
Line 6 |
28 |
\(P\) |
\((O,T)\) |
\(\{D,E,F,J,L,M,O\}\) |
Line 6 |
29 |
\(P\) |
\((O,T)\) |
\(\{D,E,F,J,L,M,O,P\}\) |
Line 9 |
30 |
\(P\) |
\((O,T,M)\) |
\(\{D,E,F,J,L,M,O,P\}\) |
Line 10-12 |
31 |
\(M\) |
\((O,T)\) |
\(\{D,E,F,J,L,M,O,P\}\) |
Line 6 |
32 |
\(T\) |
\((O)\) |
\(\{D,E,F,J,L,M,O,P\}\) |
Line 6 |
33 |
\(T\) |
\((O)\) |
\(\{D,E,F,J,L,M,O,P,T\}\) |
Line 9 |
34 |
\(T\) |
\((O,F)\) |
\(\{D,E,F,J,L,M,O,P,T\}\) |
Line 10-12 |
35 |
\(F\) |
\((O)\) |
\(\{D,E,F,J,L,M,O,P,T\}\) |
Line 6 |
36 |
\(O\) |
\(()\) |
\(\{D,E,F,J,L,M,O,P,T\}\) |
Line 6 |
Breadth-first Traversal#
The breadth-first traversal closely resembles the depth-first traversal, but instead of pushing on forward until a dead-end, it systematically explores all children, levels by levels. First, the adjacent vertices, then the vertices two edges away, then those three edges away, etc. It could be summarized as follows:
Add the entry vertex to the pending vertices
While there are pending vertices,
Pick the first pending vertex (by order of insertion)
If that vertex has not already been visited
Mark it as visited
Add to pending vertices, all vertices that can be reached from that vertex
The only difference with the depth-first traversal is the element we pick from the list of pending vertices: The breadth-first traversal uses the first inserted, whereas the depth-first traversal uses the last inserted.
breadth_first_java below illustrates how a breadth-first
traversal could look like in Java. We use a Queue to ensure we
always pick the first pending vertex, by insertion order.
1public void breadthFirstTraversal(Graph graph, Vertex entry) {
2 final var visited = new HashSet<Vertex>();
3 final var pending = new Queue<Vertex>();
4 pending.push(entry);
5 while (!pending.isEmpty()) {
6 var current = pending.remove(0);
7 if (!visited.contains(current)) {
8 System.out.println(current);
9 visited.add(current);
10 for (var eachEdge: graph.edgesFrom(current)) {
11 pending.push(eachEdge.target)
12 }
13 }
14 }
15}
Consider again the “friendship” graph introduced in above in
depth_first_example and reproduced below on
breadth_first_example. A breadth-first traversal starting
from “Denis” proceeds by “levels”. First it looks at all the adjacent
vertices, namely Frank and Olive. Then, it looks at vertices that it
can reach from those, that is Lisa, Thomas, Mary, and Olive. And then
it continues exploring nodes one more edge away, namely John and
Peter.

Traversing a graph “breadth-first”. It enumerates vertices by “level”, as follows: Denis, Frank, Olive, Lisa, Thomas, Erik, Mary, John, Peter.#